Author: Cynthia SC (05-14-2026)
Control de calidad (QC) y cell calling en scRNA-seq
Por qué un barcode no siempre representa una célula real
Contenido
- Una idea peligrosa acerca de scRNA-seq
- ¿Qué es realmente un barcode?
- ¿Qué significa droplet-based?
- ¿Sabías que Cell Ranger ya realiza cell calling?
- ¿Por qué existen herramientas especializadas?
- ¿Qué hace EmptyDrops?
- Comparación conceptual entre tecnologías
- Relación conceptual con Seurat
- Aprender single-cell más allá de los pipelines
Una idea peligrosa acerca de scRNA-seq
Uno error muy frecuente al comenzar en análisis single-cell RNA-seq es asumir que:
1 barcode = 1 célula
En realidad, esto no es cierto. En tecnologías droplet-based como 10x Genomics, el experimento genera millones de droplets, pero muchos de ellos:
- están vacíos
- contienen RNA ambiental
- contienen múltiples células (doublets)
- o presentan señales ambiguas
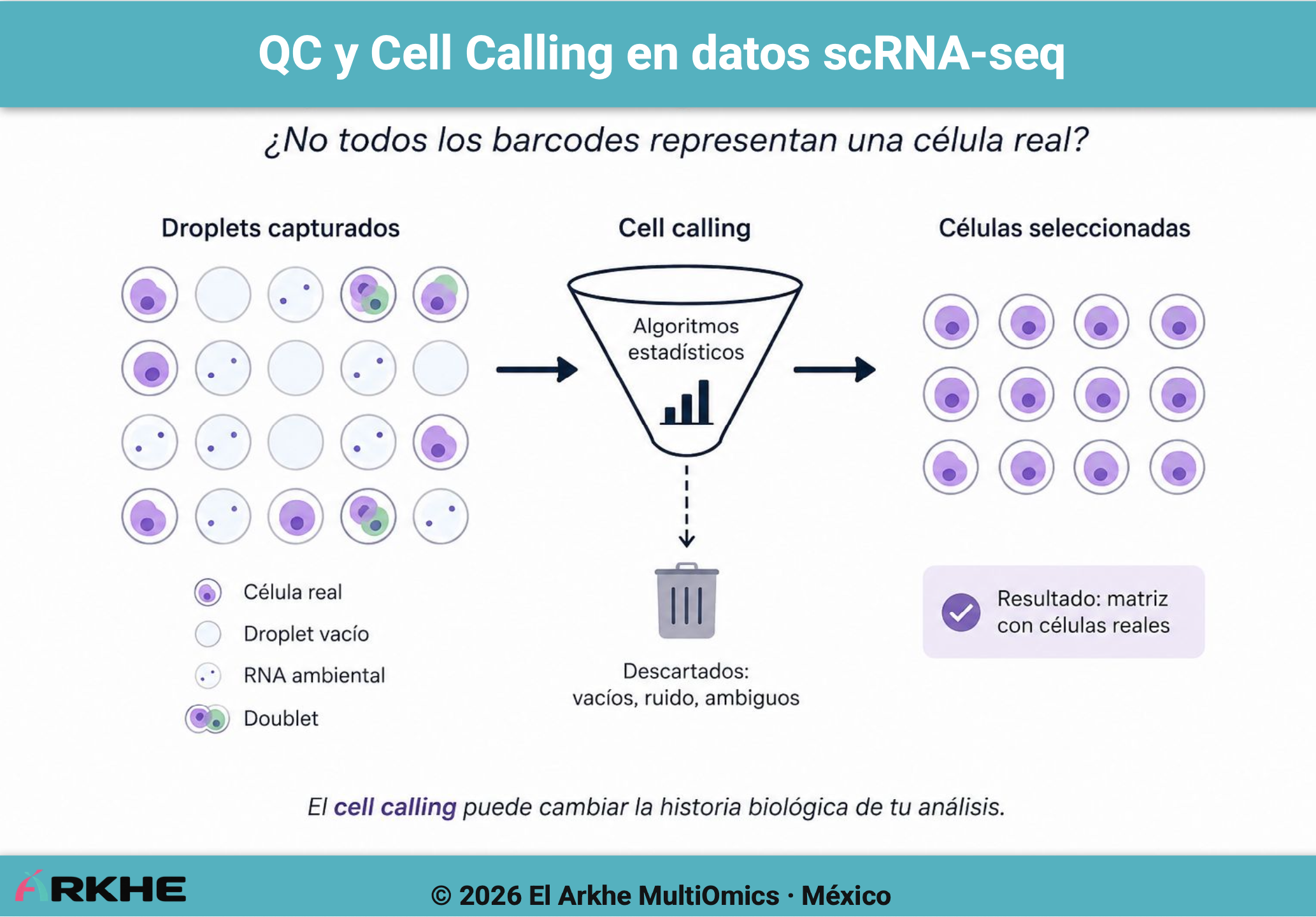
Por ello, antes del análisis biológico, existe una etapa crítica llamada:
cell calling
es decir:
decidir qué barcodes representan células reales y cuáles NO.
¿Qué es realmente un barcode?
En tecnologías droplet-based, cada droplet recibe un identificador molecular conocido como:
cell barcode
Este barcode permite asociar lecturas de secuenciación a un droplet específico.
Pero aquí aparece un detalle importante:
un barcode identifica un droplet, NO necesariamente una célula.
Por ello, una matriz sin procesar raw típica puede contener:
1,000,000+ barcodes
aunque solamente una fracción corresponde a células reales.
¿Qué significa droplet-based?
Las tecnologías droplet-based buscan encapsular células individuales dentro de gotas microscópicas (droplets) utilizando sistemas microfluídicos.
Idealmente:
1 droplet → 1 célula
Cada droplet contiene:
- una célula (idealmente)
- reactivos de retrotranscripción
- un barcode celular
- UMIs (Unique Molecular Identifiers)
Después de la secuenciación, las lecturas pueden asociarse a células individuales utilizando dichos barcodes.
El problema: no todos los droplets contienen células
En la práctica, un experimento droplet-based genera una mezcla de:
- droplets vacíos
- droplets con una célula
- droplets con múltiples células (doublets/multiplets)
- droplets contaminados con RNA ambiental libre (ambient RNA)
Por ello, los datos sin procesar contienen millones de barcodes cuya composición real no se conoce inicialmente.
Por ejemplo, una matriz raw_feature_bc_matrix.h5 típica puede contener:
1,389,510 droplets × 38,606 genes
aunque la mayoría de esos droplets están vacíos.
Esto introduce problemas específicos, que pueden resumirse como:
| Problema | Descripción |
|---|---|
| Empty droplets | Barcodes sin células reales |
| Ambient RNA | RNA libre capturado accidentalmente |
| Doublets | Dos o más células encapsuladas juntas |
| Barcode contamination | Señales espurias entre droplets |
El problema biológico detrás del QC
Cuando observamos matrices sin filtrar como:
raw_feature_bc_matrix.h5
en realidad estamos viendo una mezcla compleja de señales biológicas y técnicas.
| Tipo de barcode | Interpretación |
|---|---|
| Empty droplets | Droplets vacíos |
| Ambient RNA | RNA libre capturado accidentalmente |
| Real cells | Células reales |
| Doublets | Dos células encapsuladas juntas |
Por ello, el objetivo del QC no es simplemente “limpiar datos”. Esto es particularmente importante en datos scRNA-seq, donde la complejidad técnica es alta.
El verdadero objetivo es:
reconstruir correctamente qué señales corresponden a biología real.
¿Sabías que Cell Ranger ya realiza cell calling?
Muchos usuarios utilizan directamente:
filtered_feature_bc_matrix
Esto puede ser correcto sí conocen el patron esperado, y confían en los algoritmos de Cell Ranger, pero en algunos casos será importante entender que:
- ¿cómo fueron seleccionados esos barcodes?
- ¿qué criterios utilizó Cell Ranger?
- ¿qué barcodes quedaron fuera?
- ¿qué impacto tiene esto en downstream analysis?
Cell Ranger implementa algoritmos estadísticos para decidir qué droplets contienen células reales.
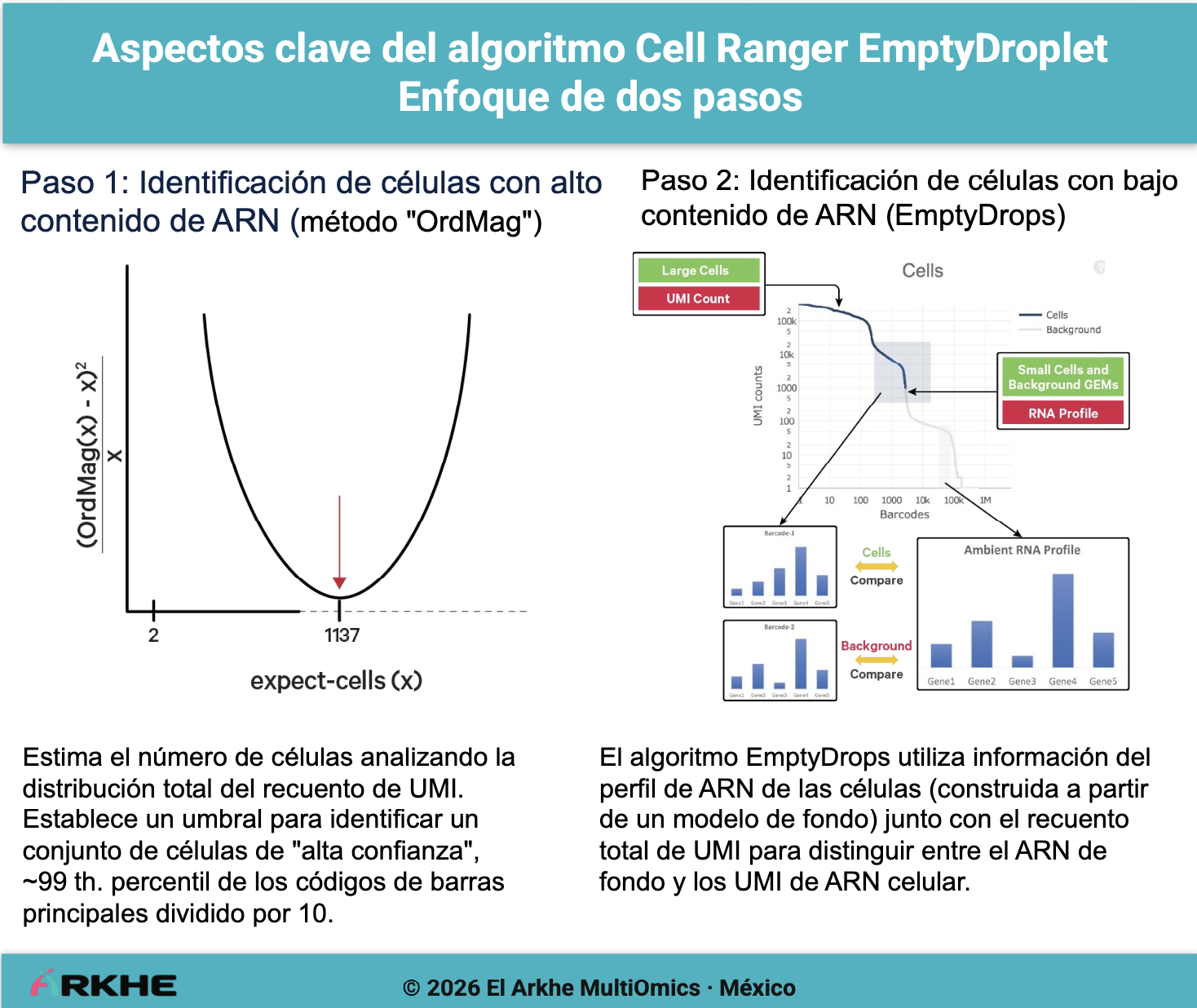
De forma simplificada:
raw matrix
↓
estimación de RNA ambiental
↓
detección estadística de droplets celulares
↓
filtered matrix
Es decir:
la matriz filtrada ya representa una interpretación computacional del experimento.
Y aquí, una pregunta importante
¿Debemos aceptar siempre los barcodes seleccionados automáticamente?
La respuesta corta es:
depende del experimento
En algunos datasets:
- Cell Ranger puede ser demasiado conservador
- células raras pueden perderse
- poblaciones de baja expresión pueden desaparecer
- o el RNA ambiental puede afectar la selección
Por ello, muchos análisis avanzados exploran también la matriz sin procesar raw.
EmptyDrops: seleccionando barcodes bajo tus propios criterios
Una de las herramientas más conocidas para este problema es EmptyDrops, propuesto por Lun et al. (2019).
La idea conceptual:
comparar cada barcode contra el perfil de RNA ambiental esperado.
Si el barcode presenta una señal significativamente distinta del ambiente:
→ probablemente contiene una célula real
Esto permite detectar:
- células de baja expresión
- poblaciones raras
- droplets ambiguos
- señales que podrían perderse en filtros automáticos
¿Por qué existen herramientas especializadas?
Muchas herramientas modernas de scRNA-seq fueron diseñadas específicamente para resolver problemas característicos de tecnologías droplet-based.
| Problema | Herramienta típica | ¿Qué hace? |
|---|---|---|
| Droplets vacíos | EmptyDrops / Cell Ranger | Identifica droplets con células reales |
| RNA ambiental | SoupX | Corrige contaminación por RNA ambiental |
| Doublets | scDblFinder | Detecta múltiples células en un mismo droplet |
| Células de baja calidad | QC downstream | Filtra células con baja complejidad o alto RNA mitocondrial |
Estas herramientas:
NO son universales, y dependen del tipo de tecnología utilizada.
¿Qué hace EmptyDrops?
El método EmptyDrops fue diseñado para tecnologías que generan grandes cantidades de droplets vacíos.
Su objetivo es distinguir droplet vacío vs droplet con célula real, utilizando matrices sin procesar (raw matrices).
Por ello, EmptyDrops solamente tiene sentido en tecnologías donde:
- existen millones de droplets
- muchos droplets están vacíos
- hay RNA ambiental detectable
No todas las tecnologías generan droplets
Es importante recordar que no todas las plataformas de scRNA-seq utilizan droplets.
Existen múltiples arquitecturas experimentales y cada una produce datos con propiedades distintas.
| Tipo de tecnología | Ejemplo |
|---|---|
| Droplet-based | 10x Genomics, Drop-seq, inDrop |
| Plate-based | Smart-seq2 |
| Microwell-based | Seq-Well |
Ejemplo conceptual: Smart-seq2
Las tecnologías plate-based funcionan de manera distinta.
Por ejemplo, en Smart-seq2:
- cada célula se deposita individualmente en un pozo
- no existen millones de droplets vacíos
- el RNA ambiental tiene un comportamiento distinto
- no se requiere cell calling
Por ello, herramientas como EmptyDrops no tienen sentido en estos datasets.
Comparación conceptual entre tecnologías
| Característica | Droplet-based | Plate-based |
|---|---|---|
| High-throughput | ✅ Muy alto | ❌ Más limitado |
| Empty droplets | ✅ Sí | ❌ No |
| Ambient RNA | ✅ Frecuente | ⚠️ Menor |
| Cell calling | ✅ Necesario | ❌ No |
| UMIs | ✅ Frecuentes | ⚠️ Variable |
| Costo por célula | ✅ Bajo | ❌ Más alto |
| Profundidad por célula | ⚠️ Moderada | ✅ Alta |
¿Por qué esto puede cambiar un análisis?
La selección de barcodes puede modificar:
- número total de células
- composición celular
- detección de poblaciones raras
- clustering
- análisis diferencial
- interpretación biológica
En otras palabras:
el cell calling puede cambiar completamente la historia biológica que observamos.
Y este es uno de los motivos por los cuales el QC en scRNA-seq es mucho más complejo que simplemente filtrar genes o UMIs.
QC no significa únicamente “filtrar células malas”
En análisis single-cell, el QC ocurre en múltiples niveles:
| Etapa | Objetivo |
|---|---|
| Cell calling | Detectar células reales |
| Ambient RNA correction | Corregir contaminación |
| Doublet detection | Detectar múltiples células |
| QC downstream | Filtrar células de baja calidad |
Por ello, herramientas como:
- EmptyDrops
- SoupX
- scDblFinder
existen porque los problemas biológicos y técnicos son distintos.
Relación conceptual con Seurat
Es importante enfatizar que Seurat es una plataforma de análisis downstream y no reemplaza las etapas iniciales de preprocesamiento experimental.
El flujo conceptual correcto es:
FASTQ
↓
alignment / counting
↓
cell calling
↓
QC
↓
normalización
↓
clustering
↓
análisis downstream
Por ello:
EmptyDropspertenece a la fase de cell calling- Seurat comienza típicamente después de esta etapa
Lo importante no es memorizar herramientas
La verdadera pregunta en scRNA-seq no es:
“¿Qué comando debo correr?”
Sino:
“¿Qué representa realmente este barcode?”
Comprender esto cambia completamente la forma de analizar datos single-cell.
Aprender single-cell más allá de los pipelines
Gran parte de los tutoriales modernos muestran únicamente:
Read10X()
→ CreateSeuratObject()
→ NormalizeData()
→ RunUMAP()
Pero rara vez explican:
- qué ocurrió antes
- cómo fueron seleccionadas las células
- qué decisiones estadísticas tomó el pipeline
- o qué sesgos podrían introducirse
Comprender estas etapas mejora enormemente la interpretación biológica y evita aplicar herramientas como si fueran universales.
Recursos de consulta
© 2026 El Arkhe MultiOmics · México